In ParaView, the prefix "Para" stands for "parallel" : How can we activate parallelism in ParaView ?
Connecting to the pvserver
If not already done, start Paraview and click the menu item : File/connect, then select the my_pvserver line and click the Connect button. You are now connected to the pvserver, as  indicated in the Pipeline browser window (see figure). Besides, if you look at the window from which you launched pwserver, you should see this message :
indicated in the Pipeline browser window (see figure). Besides, if you look at the window from which you launched pwserver, you should see this message :
Loading and displaying data
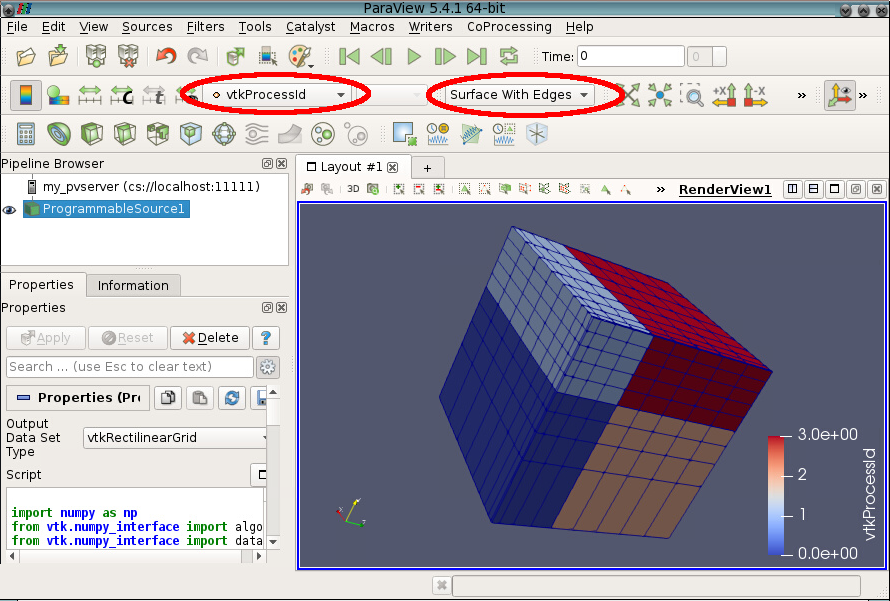
- Figure obtained with 4 processors, using the python script rectilinear.py
You can now load your datafiles, your state files, your python scripts, exactly as usual.
Warning : to read a python script, you must use the menu item : Tools/Python shell/Run script.
Data will be read by pvserver, and rended and displayed by ParaView. You should have a new property available with your data : vtkProcessId
You can easily display the domain decomposition made pvserver for reading your data (see the figure).
If you execute a filter, it will be executed by pvserver, thus using several cores, which can lead to faster execution if you have a huge quantity of data to treat